The officer Lu Hsuan once said to Master Nan Ch'uan: “Heaven, earth, and I have the same root; myriad things and I are one body. This is quite marvelous.”
Nan Ch'uan pointed to a flower in the garden and replied, “People these days see this flower as a dream.”
In machine learning for cheminformatics, we often mistake the map for the territory. Random data splits are the standard for training and validation. While this approach appears objective, it lacks control over the biases inherent in chemical datasets.[1-3]
The Problem of Randomness
Biases—such as the relationship between structural similarity and bioactivity[4], or the presence of activity cliffs (where small structural changes cause large bioactivity differences)[5]—significantly influence model training. A random split obscures these critical factors, limiting our understanding of model performance under real-world conditions.
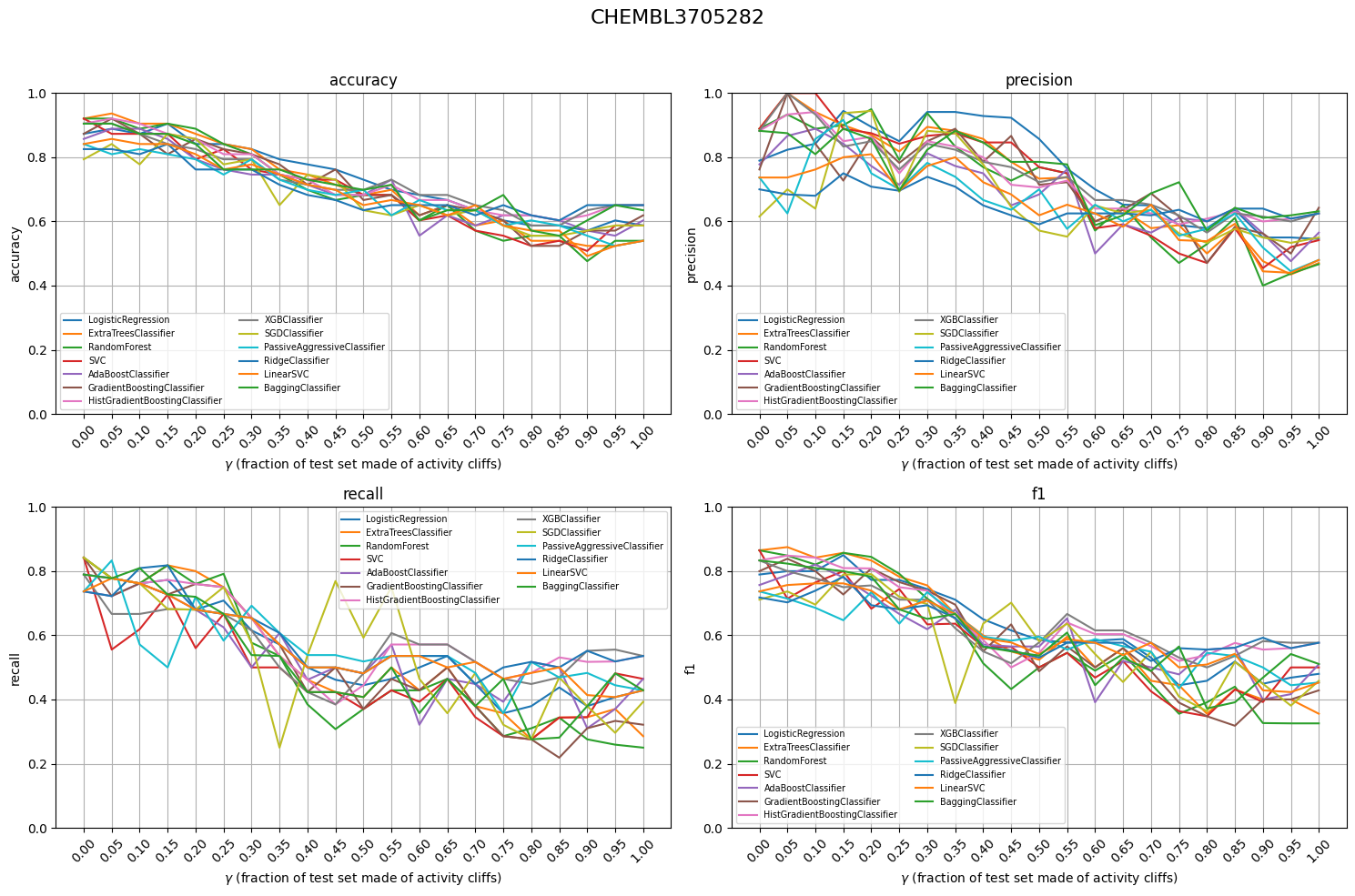
Analogue Split addresses this by introducing a controlled, biased splitting mechanism using a parameter, γ (gamma), to adjust test set composition. This approach creates a series of test sets that are explicitly designed to stress-test the model's ability to handle within-series and between-series predictions.
But a rigorous test requires a rigorous yardstick; creating a harder challenge is futile if we measure success with a broken ruler.
Gross performance metrics like accuracy and F1 score can be deceptive.[6] I advocate for biased validation because models are only as good as the data they are validated against. With Analogue Split, we take a step closer to selecting models that don't just perform well, but perform meaningfully. After all, in practice, it is not about being right; it is about being useful.
References
Acknowledgements
Special thanks to Andreas Bender, Daniel Svozil, Martin Sicho, Wim Dehaen, Ivan Čmelo, Srijit Seal, and Yoann Gloaguen for inspiring and shaping these ideas.